
.svg?width=13&quality=80&auto=webp&format=auto&cache=true&immutable=true&cache-control=max-age%3D31536000 "Top Navigation - Sign in - Icon")



At the NorthSec Conference 2026, Sophos Principal Data Scientist François Labrèche presented a talk titled ‘A Needle in a Haystack: Identifying an Infostealer Attack Through Trillions of Events in a Large-scale Modern SOC.’
This research addresses one of the largest problems Security Operations Center (SOC) analysts face nowadays: alert fatigue due to the large quantity of security alerts to triage, many of which are irrelevant or benign.
Some past research has explored reducing false positives and noise in SOC alerting frameworks, but there are two persistent limitations, which are at odds with the reality of a large-scale modern SOC:
- Published approaches often focus on Intrusion Detection System (IDS) alerts
- The scale of datasets in previous research does not adequately reflect a modern large-scale SOC's size, with datasets often varying in size from 100,000 to 10 million events/alerts (examples: 1, 2, 3, 4, 5, 6).
François presented an alternative, and more realistic, approach: multiple layers of detection and filtering frameworks of increasing complexity, that target different layers of the alerting pipeline.
To show how a multi-layered approach can help hunt for threats, François used a two-week window of alerts from our telemetry, comprising trillions of events, and combined alert deduplication, individual rule- and ML-based detectors, alert suppression, and a supervised ML-based alert prioritization model to dramatically reduce the noise.
As a result of this reduction, François showed how it’s possible to pinpoint a genuine infostealer attack.
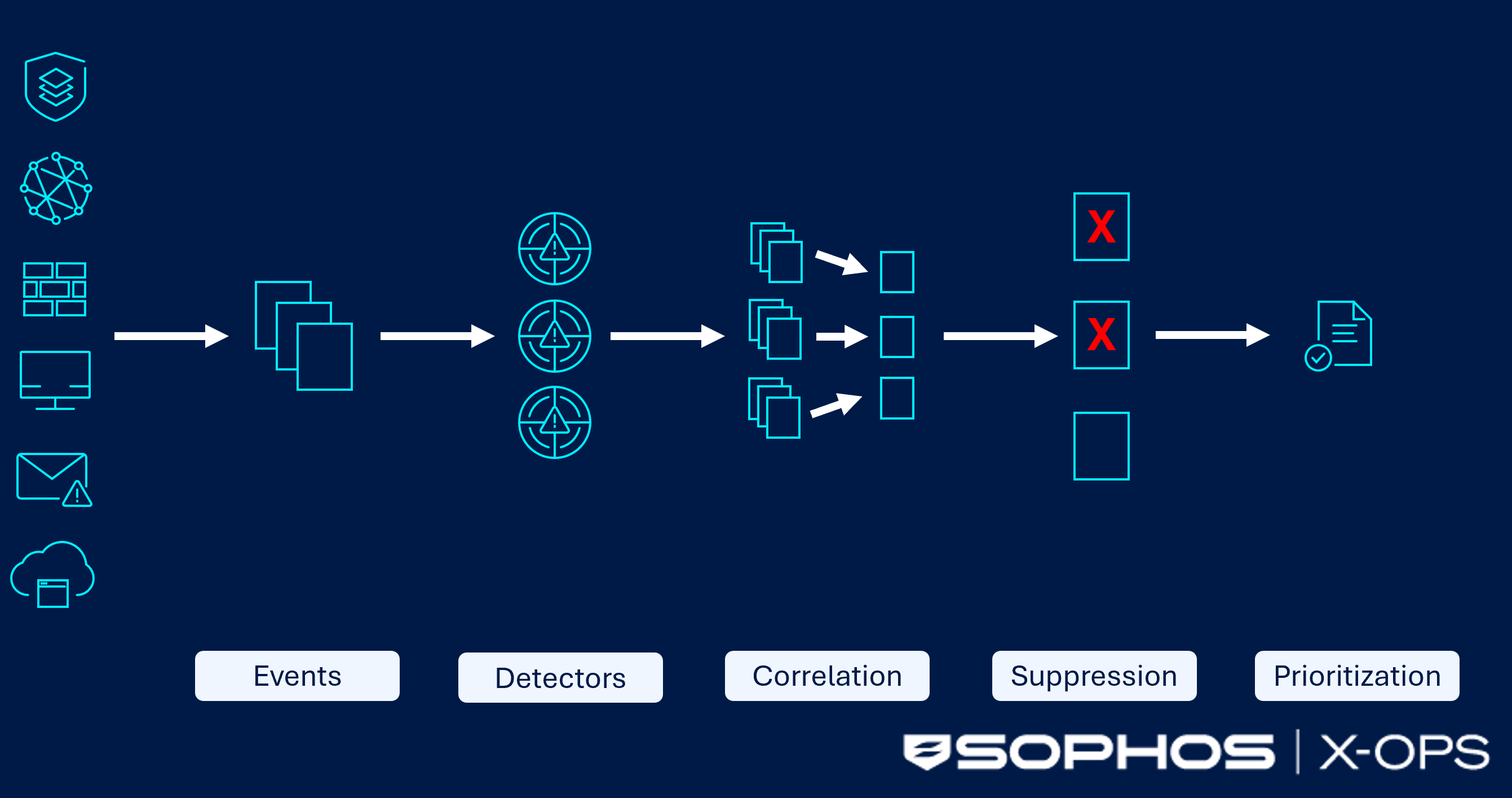
Figure 1: An overview of the multi-step pipeline
The alert pipeline
To gather the test data, François used telemetry from Taegis XDR, which ingests over 800 billion events every day. Over the selected two-week period, this represents a staggering 11.8 trillion events. These events come from various sources, and range from authentications, file modifications, process activity, IDS alerts, and more.
Detectors
The first step in the alerting pipeline is detectors. Their goal is to detect possible threats in customers' security data. With so many different threat vectors, detectors use a few different approaches, varying in complexity. These fit into four categories:
Simple indicators and rules
These are the simplest filters, and focus on common IOC matches based on string matches and regex matches. Examples of these include matching on an exact URL or IP, or a parent and child process combination.
Correlation rules
These rules are slightly more complex, and look at historical actions to identify anomalous behavior: for example, a user logging for the first time to an admin server, where they previously only accessed development servers.
ML models
Lastly, some ML models run as detectors on a specific subset of alerts, aiming at detecting one specific type of threat. Two examples of these are a domain generation algorithm (DGA) model, to predict if a URL is computationally generated, and a Hands-On-Keyboard detector to predict if a command line is run by a malicious actor, as opposed to a legitimate IT script.
The DGA detector is a supervised ML model, trained on historical data with URLs labelled as generated by DGA. It employs Long Short-Term Memory (LSTM), and is trained with URLs as input, so that it can be applied to new URLs to identify if they are the result of DGAs.
The Hands-On-Keyboard detector works differently: it’s still supervised ML, but it employs simpler logistic regression for training, and uses multiple models to identify if a command line is malicious. This detector applies to command lines, so features are built from typical command line characteristics, such as:
- Command length
- Whether the user/process is admin
- Arguments in the command line: (/add, /create, procdump, etc)
- Actual commands in the command line: (echo, cmd, etc)
Filtering
This detector filtering step is the largest one, given that only positive matches continue forward. This resulted in only 0.02% of events being promoted to an ‘alert.’ While this results in a large reduction, it still left around 2.6 billion alerts from the initial 11.8 trillion events: a number considerably too large for manual triage. Alerts typically linked to infostealer activity still numbered close to 16 million.
Deduplication and correlation
The second step of the multi-step pipeline is deduplication and correlation.
Deduplication
Deduplication consists of grouping multiple alerts representing a common signal. These include, for example, Denial of Service (DoS) attacks, scanning activity, and password sprays, where hundreds or thousands of alerts are combined into a single grouped alert. Depending on the use case, grouping is done on different entities: a DOS will target a single URL or IP from multiple sources, whereas scanning will target multiple machines from a single source.
Correlation
In a similar fashion, correlation is used to group different alerts linked to a known pattern of attack on the entities: for example, the same user on the same machine being the victim of post exploitation activity.
After deduplication and correlation, 9.5% of the alerts remained. For the two-week window, approximately 2.6 billion alerts were grouped into 251.4 million alerts. After this step, alerts typically linked to infostealer activity still numbered 780,000.
Suppression
Next is the third step in the alert pipeline: suppression. These filtered alerts are dependent on the context surrounding an alert or a customer. Some examples include the suppression of false positive alerts based on erroneous threat intelligence or IOCs, or a specific organization already having security measures in place for specific alert types. For example, if an organization runs a vulnerability scanner internally, that scan’s alerts would be suppressed, since it is known authorized activity.
In total, 16% of remaining alerts were suppressed. In real terms, the 251.4 million grouped alerts, after suppression, were down to 211 million.
Prioritization
The last step of the alerting pipeline is the prioritization step. XDR and EDR detections are often associated with a hardcoded severity set by the detector. While this severity isn’t necessarily 100% precise, it can be used to split the alerts into two categories:
- High and critical severity alerts
- Medium and lower severity alerts
Higher severity alerts can be used to train more complex models, while the medium severity and lower alerts can be kept aside, to provide subsequent context on what the models identify as threats. Out of the 211 million alerts, 138,917 alerts were high and critical.
On these alerts, more complex approaches could now be applied. From 6 months of data, a dataset of approximately 1.8 million alerts was used to train a global ML model.
This alert prioritization step has two goals:
- Automatically close alerts with a low probability of being an actual threat
- Increase the severity of alerts with a high probability of being a threat
A supervised ML model was trained on historical data using analyst decisions as labels. This model included both static (including the number of entities in the alert, and MITRE techniques) and dynamic features. The latter were built by identifying rates of past incidents for similar alerts. For example:
- Are past similar alerts investigated for this client? Are they for other clients?
- Have similar alerts been investigated in the past 24 hours, the past week, or the past month?
- Were similar entities investigated?
These questions were encoded as ratios that built the features for a Gradient Boosted Trees Classifier, which enabled inference in a streaming fashion over the large number of alerts observed every minute.
The most important factors to keep track of for this model were live monitoring metrics. François tracked both the false negative rate and the alert volume reduction, where the threshold on the model's predictions decided how many false negatives was an acceptable trade-off for the alert volume reduction.
In this context, a false negative is an alert incorrectly identified as benign while it was a threat. A low number of false negatives is acceptable, as an incident will typically have multiple alerts associated with it, but with a larger false negative rate there is a risk of completely missing an attack.
Running this model in streaming, it provided an additional reduction of 57,344 alerts, bringing the final count for a two-week period to 81,573.
While this number still seems large, it includes events from multiple organizations. Each organization had on average fewer than 50 alerts.
Identifying infostealer activity
After running the multi-step pipeline, it became possible to identify infostealer activity in the two-week window. Looking at the remaining alerts from one specific customer, a small number of threats appear:
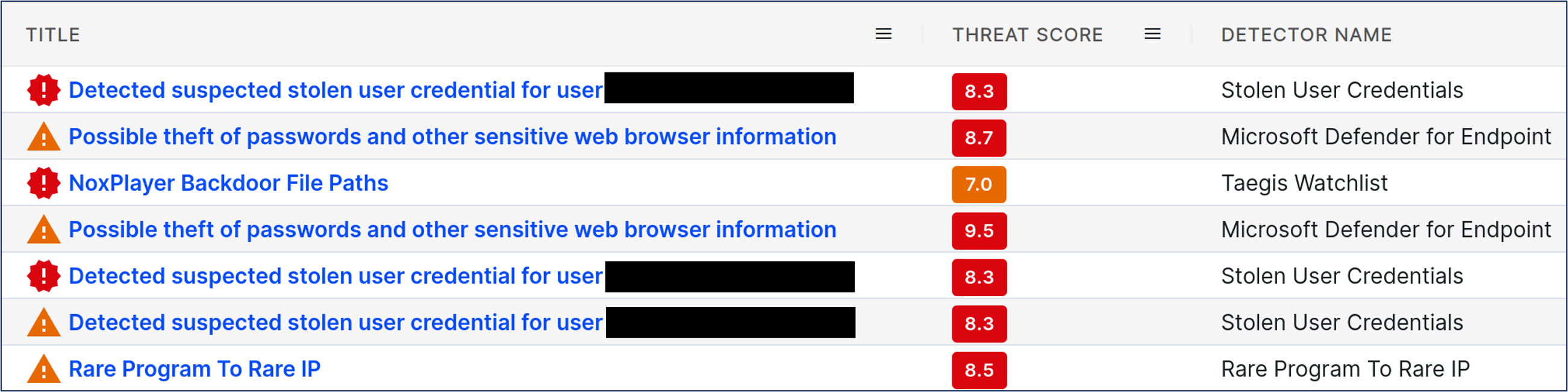
Figure 2: The remaining alerts for one customer
Here, the title, the probability output of the prioritization model, and the detector name of alerts are shown. The majority of these appear linked to infostealer activity. However, exploring the suspected stolen user credential alerts further revealed that these were false positives. After the multiple filtering steps, some benign/non-actionable alerts remained. However, the two ‘Possible theft of passwords’ alerts had a high threat score, and warrant further exploration.
Here’s where the medium and lower severity alerts, close in time for the same user and same machine, come into their own. When inspecting an alert, these provide context on the threat.

Figure 3: Including medium and lower severity alerts. Note that both malware detection alerts have a low threat score, likely because these are often false positives; only when seen with other infostealer signals can we confidently say that the user’s machine is compromised
The activity began with an anomalous signal on a program, but with an infostealer malware detection following it, and a behavioural alert on possible password theft. This repeated twice, and painted a picture of an infostealer malware on this user’s machine.
At this point, Sophos contacted the customer and incident response steps were initiated to contain the attack.
Conclusion
This research demonstrates that, when it comes to tackling the huge number of data points in a large-scale modern SOC, a multi-step alert pipeline can make the task of identifying malicious activity – infostealers, in this case – much more manageable.
From an initial 11.8 trillion events, the filtering steps brought that number down to 81,573 high and critical alerts (with an average of fewer than 50 alerts per organization), by employing detectors, deduplication and correlation, suppression, and prioritization.
Manual triage of these remaining alerts identified an infostealer attack through two critical alerts, using the remaining lower severity alerts as context.
Future work on this alert pipeline includes exploring an adaptation of the alert prioritization step to be applied to groups of alerts identified as part of a single incident. Additional features could be built from the aggregated data of alerts in the incident.