
.svg?width=13&quality=80&auto=webp&format=auto&cache=true&immutable=true&cache-control=max-age%3D31536000 "Top Navigation - Sign in - Icon")



La detección de anomalías en ciberseguridad promete desde hace tiempo la capacidad de identificar amenazas resaltando las desviaciones del comportamiento esperado. Sin embargo, cuando se trata de identificar comandos maliciosos, su aplicación práctica a menudo da lugar a altas tasas de falsos positivos, lo que la hace cara e ineficaz. Pero con las recientes innovaciones en IA, ¿hay algún nuevo ángulo que aún no hayamos explorado?
En nuestra charla en Black Hat USA 2025, presentamos nuestra investigación sobre el desarrollo de un proceso que no depende de la detección de anomalías como punto de fallo. Al combinar la detección de anomalías con modelos de lenguaje grandes (LLM), podemos identificar con confianza los datos críticos que pueden utilizarse para mejorar un clasificador de línea de comandos específico.
El uso de la detección de anomalías para alimentar un proceso diferente evita las tasas de falsos positivos potencialmente catastróficas de un método no supervisado. En su lugar, creamos mejoras en un modelo supervisado dirigido a la clasificación.
Inesperadamente, el éxito de este método no dependió de que la detección de anomalías localizara líneas de comando maliciosas. En cambio, la detección de anomalías, cuando se combina con el etiquetado basado en LLM, produce un conjunto notablemente diverso de líneas de comando benignas. El aprovechamiento de estos datos benignos al entrenar clasificadores de línea de comando reduce significativamente las tasas de falsos positivos. Además, nos permite utilizar los abundantes datos existentes sin tener que buscar agujas en un pajar, que son las líneas de comando maliciosas en los datos de producción.
En este artículo, exploraremos la metodología de nuestro experimento, destacando cómo la diversidad de datos benignos identificados a través de la detección de anomalías amplía la comprensión del clasificador y contribuye a crear un sistema de detección más resistente.
Al cambiar el enfoque de buscar únicamente anomalías maliciosas a aprovechar la diversidad benigna, ofrecemos un posible cambio de paradigma en las estrategias de clasificación de líneas de comando.
Un enfoque fundamentalmente nuevo
Los profesionales de la ciberseguridad suelen tener que encontrar un equilibrio entre los costosos conjuntos de datos etiquetados y las detecciones ruidosas no supervisadas. El etiquetado benigno tradicional se centra en comportamientos benignos poco complejos y observados con frecuencia, ya que es fácil de lograr a gran escala, lo que excluye inadvertidamente los comandos benignos raros y complicados. Esta brecha hace que los clasificadores clasifiquen erróneamente los comandos benignos sofisticados como maliciosos, lo que aumenta las tasas de falsos positivos.
Los recientes avances en los LLM han permitido un etiquetado basado en IA muy preciso a gran escala. Probamos esta hipótesis etiquetando las anomalías detectadas en la telemetría real de producción (más de 50 millones de comandos diarios) y logramos una precisión casi perfecta en las anomalías benignas. Utilizando la detección de anomalías de forma explícita para mejorar la cobertura de los datos benignos, nuestro objetivo era cambiar el papel de la detección de anomalías, pasando de identificar de forma errática los comportamientos maliciosos a destacar de forma fiable la diversidad benigna. Este enfoque es fundamentalmente nuevo, ya que la detección de anomalías tradicionalmente da prioridad a los descubrimientos maliciosos en lugar de mejorar la diversidad de las etiquetas benignas.
Mediante la detección de anomalías junto con el etiquetado benigno automatizado y fiable de LLM avanzados, concretamente el modelo o3-mini de OpenAI, aumentamos los clasificadores supervisados y mejoramos significativamente su rendimiento.
Cómo lo hicimos
Recopilación de datos y caracterización
Comparamos dos implementaciones distintas de recopilación de datos y caracterización durante el mes de enero de 2025, aplicando cada implementación diariamente para evaluar el rendimiento a lo largo de una línea temporal representativa.
Implementación a gran escala (toda la telemetría disponible)
El primer método se aplicó a toda la telemetría diaria de Sophos, que incluía unos 50 millones de líneas de comando únicas al día. Este método requirió escalar la infraestructura utilizando clústeres Apache Spark y el escalado automatizado a través de AWS SageMaker.
Las características del enfoque a gran escala se basaron principalmente en la ingeniería manual específica del dominio. Calculamos varias características descriptivas de la línea de comando:
Las características basadas en la entropía medían la complejidad y la aleatoriedad de los comandos.
Las características a nivel de caracteres codificaban la presencia de caracteres específicos y tokens especiales.
Las características a nivel de tokens capturaban la frecuencia y la importancia de los tokens en las distribuciones de la línea de comandos.
Las comprobaciones de comportamiento se centraban específicamente en patrones sospechosos comúnmente relacionados con intenciones maliciosas, como técnicas de ofuscación, comandos de transferencia de datos y operaciones de volcado de memoria o credenciales.
Implementación de incrustaciones a escala reducida (subconjunto muestreado)
Nuestra segunda estrategia abordó las preocupaciones sobre la escalabilidad utilizando subconjuntos muestreados diariamente con 4 millones de líneas de comando únicas al día. La reducción de la carga computacional permitió evaluar las compensaciones de rendimiento y la eficiencia de los recursos de un enfoque menos costoso.
Cabe destacar que las incrustaciones de características y el procesamiento de anomalías para este enfoque podrían ejecutarse de forma viable en instancias GPU de Amazon SageMaker y instancias CPU de EC2, lo que reduciría significativamente los costes operativos.
En lugar de la ingeniería de características, el método muestreado utilizó incrustaciones semánticas generadas a partir de un modelo de incrustaciones de transformadores preentrenado diseñado específicamente para aplicaciones de programación: Jina Embeddings V2. Este modelo está explícitamente preentrenado en líneas de comando, lenguajes de scripting y repositorios de código. Las incrustaciones representan los comandos en un espacio vectorial de alta dimensión y semánticamente significativo, lo que elimina la carga de la ingeniería manual de características y captura de forma inherente las complejas relaciones entre los comandos.
Aunque las incrustaciones de los modelos basados en transformadores pueden requerir un gran esfuerzo computacional, el menor tamaño de los datos de este enfoque hizo que su cálculo fuera manejable.
El empleo de dos metodologías distintas nos permitió evaluar si podíamos obtener reducciones computacionales sin una pérdida considerable del rendimiento de la detección, lo que supone una valiosa información para la implementación en producción.
Técnicas de detección de anomalías
Tras la caracterización, detectamos anomalías con tres algoritmos de detección de anomalías no supervisados, cada uno de ellos elegido por sus características de modelado distintivas. El «bosque de aislamiento» identifica particiones aleatorias dispersas; un «k-means modificado» utiliza la distancia del centroide para encontrar puntos atípicos que no siguen las tendencias comunes de los datos; y el «análisis de componentes principales (PCA)» localiza los datos con grandes errores de reconstrucción en el subespacio proyectado.
Deduplicación de anomalías y etiquetado LLM
Una vez completado el descubrimiento preliminar de anomalías, abordamos una cuestión práctica: la duplicación de anomalías. Muchos comandos anómalos solo diferían mínimamente entre sí, como un pequeño cambio de parámetro o una sustitución de nombres de variables. Para evitar redundancias y sobrevalorar inadvertidamente ciertos tipos de comandos, establecimos un paso de deduplicación
Calculamos las incrustaciones de la línea de comandos utilizando el modelo transformador (Jina Embeddings V2) y, a continuación, medimos la similitud de los candidatos a anomalías con comparaciones de similitud coseno. La similitud coseno proporciona una medida vectorial robusta y eficiente de la similitud semántica entre representaciones incrustadas, lo que garantiza que el análisis de etiquetado posterior se centre en anomalías sustancialmente nuevas.
Posteriormente, las anomalías se clasificaron mediante etiquetado automatizado basado en LLM. Nuestro método utilizó el LLM de razonamiento o3-mini de OpenAI, elegido específicamente por su eficaz comprensión contextual de los datos textuales relacionados con la ciberseguridad, gracias a su ajuste general para diversas tareas de razonamiento.
Este modelo asignó automáticamente a cada anomalía una etiqueta clara de benigna o maliciosa, lo que redujo drásticamente las costosas intervenciones de los analistas humanos.
La validación del etiquetado LLM demostró una precisión excepcionalmente alta para las etiquetas benignas (cercana al 100 %), confirmada por la puntuación manual de analistas expertos durante una semana completa de datos de anomalías. Esta alta precisión permitió la integración directa de las anomalías benignas etiquetadas en las fases posteriores para el entrenamiento del clasificador con alta confianza y mínima validación humana.
Este proceso metodológico cuidadosamente estructurado, desde la recopilación exhaustiva de datos hasta el etiquetado preciso, dio como resultado diversos conjuntos de datos de comandos etiquetados como benignos y redujo significativamente las tasas de falsos positivos cuando se implementó en modelos de clasificación supervisada.
Resultados y conclusiones
Las implementaciones a escala real y a escala reducida dieron como resultado dos distribuciones separadas, como se puede ver en las figuras 1 y 2, respectivamente. Para demostrar la generalizabilidad de nuestro método, ampliamos dos conjuntos de datos de entrenamiento de referencia independientes: una referencia de expresiones regulares (RB) y una referencia agregada (AB). La referencia de expresiones regulares obtenía las etiquetas de reglas estáticas basadas en expresiones regulares y estaba destinada a representar uno de los procesos de etiquetado más sencillos posibles. La referencia agregada obtenía las etiquetas de reglas basadas en expresiones regulares, datos de entornos de pruebas, investigaciones de casos de clientes y telemetría de clientes. Esto representa un proceso de etiquetado más maduro y sofisticado.
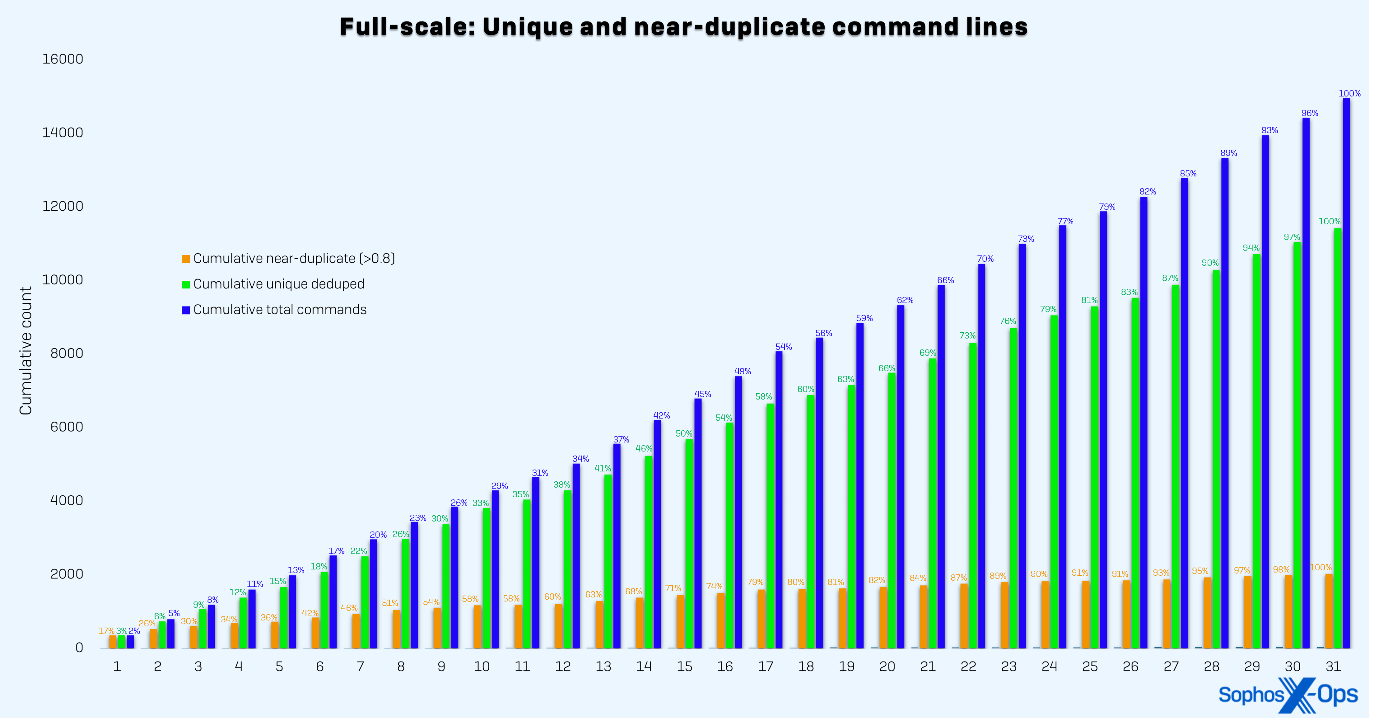
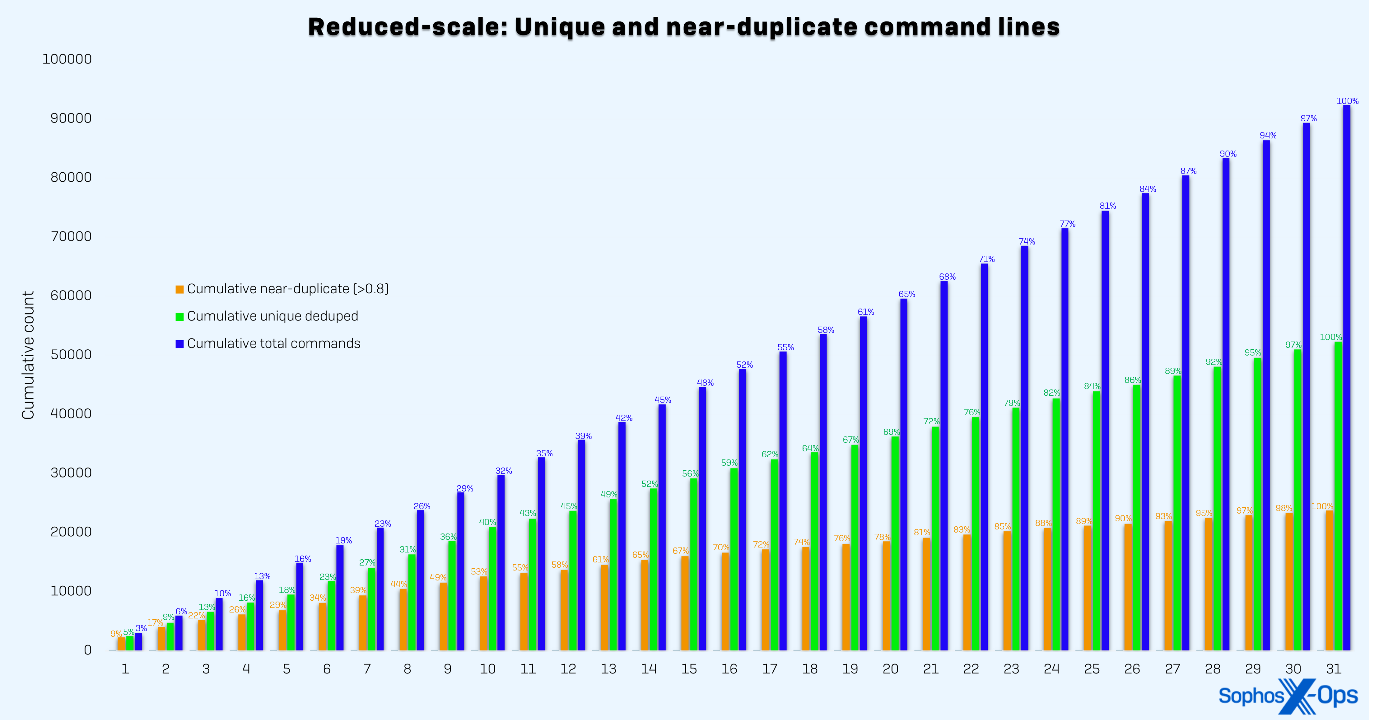
Figura 2: Distribución acumulativa de las líneas de comando recopiladas por día durante el mes de prueba utilizando el método a escala reducida. La escala reducida se estabiliza más lentamente porque es probable que los datos muestreados encuentren más óptimos locales
| Conjunto de entrenamiento | Prueba de incidentes AUC | Prueba de división de tiempo AUC |
| Base agregada (AB) | 0.6138 | 0.9979 |
| AB + escala completa | 0.8935 | 0.9990 |
| AB + escala reducida Combinado | 0.8063 | 0.9988 |
| Regex Baseline (RB) | 0.7072 | 0.9988 |
| RB + Escala completa | 0.7689 | 0.9990 |
| RB + Escala reducida Combinado | 0.7077 | 0.9995 |
Tabla 1: Área bajo la curva para los modelos de referencia agregados y de referencia regex entrenados con datos benignos adicionales derivados de anomalías. El conjunto de entrenamiento de referencia agregado consta de datos de clientes y de sandbox. El conjunto de entrenamiento de referencia regex consta de datos derivados de regex
Como se puede ver en la Tabla 1, evaluamos nuestros modelos entrenados tanto en un conjunto de pruebas de división temporal como en un benchmark etiquetado por expertos derivado de investigaciones de incidentes y un marco de aprendizaje activo. El conjunto de pruebas de división temporal abarca tres semanas inmediatamente posteriores al periodo de entrenamiento. El benchmark etiquetado por expertos se asemeja mucho a la distribución de producción de los modelos implementados anteriormente.
Al integrar datos benignos derivados de anomalías, mejoramos el área bajo la curva (AUC) en el benchmark etiquetado por expertos de los modelos de referencia agregados y regex en 27,97 puntos y 6,17 puntos, respectivamente.
Conclusión
En lugar de una clasificación maliciosa directa e ineficaz, demostramos la excepcional utilidad de la detección de anomalías para enriquecer la cobertura de datos benignos en la cola larga, un cambio de paradigma que mejora la precisión del clasificador y minimiza las tasas de falsos positivos.
Los LLM modernos han permitido automatizar los procesos de etiquetado de datos benignos, algo que hasta hace poco era imposible. Nuestro proceso se integró a la perfección en un proceso de producción ya existente, lo que pone de relieve su carácter genérico y adaptable.


