
.svg?width=13&quality=80&auto=webp&format=auto&cache=true&immutable=true&cache-control=max-age%3D31536000 "Top Navigation - Sign in - Icon")





Las conversaciones sobre las «amenazas de la IA» suelen caer en uno de estos dos extremos. Por un lado, el sensacionalismo: afirmaciones sin verificar que no resisten un análisis riguroso y suscitan muchas críticas. Por otro, el desdén: solo son viejas técnicas de ataque con un nuevo nombre.
Como ocurre con la mayoría de dicotomías de este tipo, la verdad probablemente esté en algún punto intermedio. Los actores maliciosos utilizan y experimentan con la IA de diferentes maneras, tanto para facilitar los ataques como para convertirla en objetivo. Por diversas razones, resulta difícil hacerse una idea del verdadero alcance de este fenómeno, pero, como señalamos en nuestro informe sobre las actitudes hacia la IA en los foros delictivos, se ha producido un giro hacia la adopción de la IA en algunas herramientas. Otros estudios —como el informe «Panorama de amenazas para 2025» de la ENISA— describen un uso creciente y real de la IA en todo el ecosistema del cibercercen (incluido el phishing generado por IA, la clonación de voz, los deepfakes, la creación de scripts y el reconocimiento asistido por IA), al tiempo que señalan, tal y como hicimos en nuestra investigación, que otras aplicaciones maliciosas, como el malware generado por IA, siguen por el momento en el ámbito de las demostraciones controladas más que como amenazas activas.
Para ayudar a rastrear y clasificar las amenazas de IA, Sophos X-Ops ha creado una taxonomía de trabajo. Divide el problema en dos categorías principales: Uso malicioso de la IA y Ataques maliciosos dirigidos a la IA. Cada categoría contiene varias subcategorías de ataques, basadas en incidentes observados en el mundo real, nuestra investigación en curso sobre ataques de IA o ataques que evaluamos como posibilidades futuras realistas.
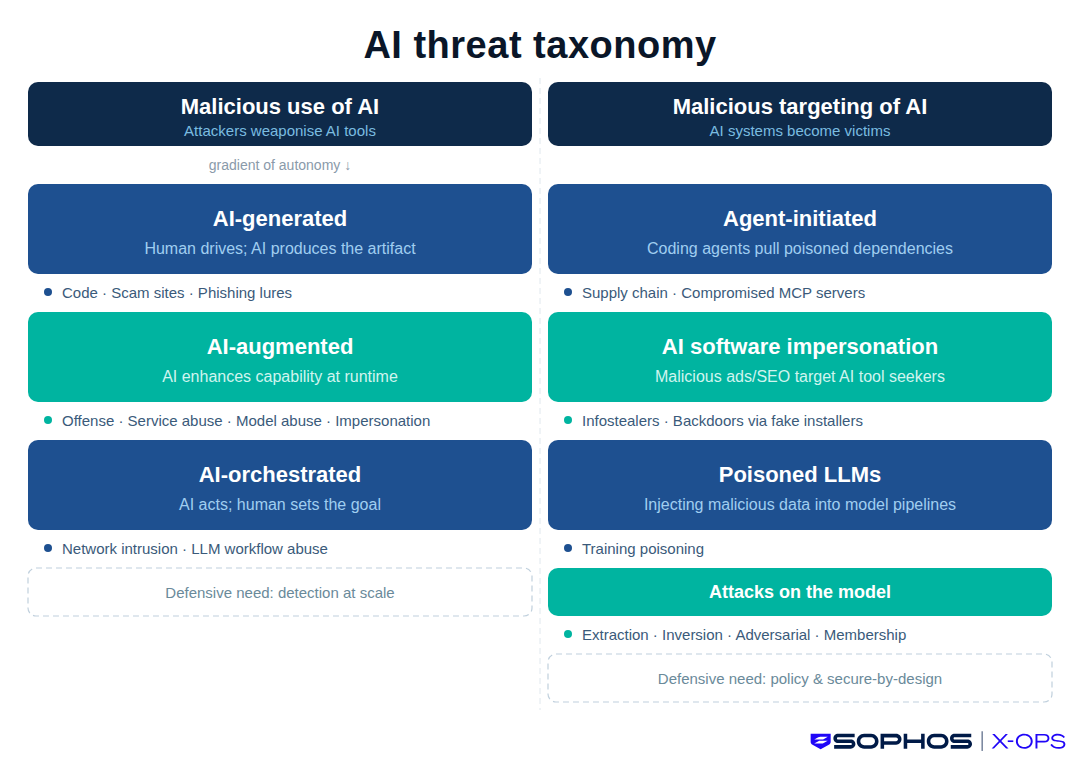
Figura 1: resumen de la taxonomía de amenazas de IA
Primera parte: uso malicioso de la IA
Probablemente esta sea la categoría en la que piensa la mayoría de la gente cuando oye hablar de «amenazas de IA»: atacantes que abusan de herramientas populares de IA. Pero la amenaza es más complesa, el nivel de implicación de la IA varía y lo mismo ocurre con la respuesta defensiva adecuada.
Una forma útil de abordar las subcategorías es considerarlas como un gradiente de autonomía. «Generado por IA» implica que el humano «conduce», con la IA como herramienta en el asiento del copiloto. «Potenciado por IA» significa responsabilidad compartida. En los ataques «orquestados por IA», la IA conduce y el humano es el copiloto que marca el destino.
Vale la pena señalar aquí, como ya hemos señalado en algunas de nuestras investigaciones anteriores sobre este tema, que todas estas subcategorías —pero especialmente los ataques orquestados por la IA— reducen el umbral mínimo de capacidad. Los actores maliciosos con intención y oportunidad, pero con medios limitados, ahora pueden acceder a recursos y habilidades más avanzados «a su antojo», ampliando así la población de actores maliciosos viables en el extremo inferior de la curva de habilidades.
Generado por IA
El uso más sencillo: la IA generativa produce un artefacto —código, una web falsa, un señuelo de phishing— y un humano se hace cargo a partir de ahí.
- Código generado por IA: un actor malicioso usa un asistente de programación, como Cursor, para crear scripts, exploits, cargas útiles o herramientas, que luego el operador humano implementa. Por ejemplo: entre diciembre de 2025 y febrero de 2026, un actor malicioso atacó a varias organizaciones gubernamentales mexicanas, utilizando tanto Claude Code de Anthropic como GPT de OpenAI para generar scripts y herramientas. Más recientemente, las TTP relacionadas con The Gentlemen, un grupo de ransomware, indican el uso de ChatGPT, Gemini y Claude para el desarrollo, y los chats filtrados del grupo lo confirman.
- Sitio web generado por IA: publicamos un estudio sobre esto ya en 2023: sitios web fraudulentos y portales maliciosos que la IA generativa ayuda a crear, que logran un gran volumen y un acabado impecable con poco o ningún esfuerzo humano.
- Señuelo generado por IA: guiones, pretextos y señuelos de ingeniería social redactados por un modelo de IA y enviados por un humano.
Medidas de mitigación
Las detecciones y protecciones siguen siendo válidas, porque lo que importa es el artefacto final. Por otro lado, el rendimiento, la escala y la capacidad pueden aumentar significativamente. Los defensores deben esperar más campañas, más variantes y una iteración y adaptación más rápidas.
Potenciado por IA
Un modelo de IA mejora una capacidad ya existente, pero en tiempo de ejecución.
- Apoyo ofensivo potenciado por IA: un actor malicioso usa la IA para respaldar un ataque; por ejemplo, utilizando modelos de lenguaje grande (LLM) para mejorar la escala o la profundidad de su reconocimiento y OSINT, o para automatizar el descubrimiento de vulnerabilidades y el desarrollo de exploits.
- Abuso de servicios potenciado por IA: malware que llama a una API comercial de LLM en tiempo de ejecución para generar dinámicamente comandos de ataque, en lugar de incrustarlos de forma estática en el binario. Un ejemplo destacado en 2025 fue LameHug, que el CERT-UA atribuyó (con confianza moderada) a APT28: un malware basado en Python que consultaba el modelo Qwen2.5-Coder-32B-Instruct alojado en Hugging Face para generar sobre la marcha comandos de reconocimiento y robo de datos en Windows, dirigidos contra objetivos del Gobierno ucraniano. El malware generaba comandos diferentes según el entorno, lo que hacía que el análisis estático fuera mucho menos útil y que el tráfico saliente hacia las API de IA/ML se convirtiera en una de las pocas superficies de detección fiables.
- Abuso de modelos potenciado por IA: malware que viene con un modelo integrado que, por ejemplo, genera contenido (como documentos señuelo y respuestas adpatadas al contexto) o realiza otras acciones maliciosas en un host infectado. Ten en cuenta que, por lo que sabemos, se trata de un ataque teórico en el momento de escribir este artículo, y dependería del tamaño del modelo. Por ejemplo, el llamafile de Mozilla permite distribuir y ejecutar un LLM dentro de un único archivo ejecutable. Una versión preconstruida, con los pesos incluidos, alcanza un tamaño ligeramente inferior al límite de ejecución de 4 GB de Windows (por lo que sigue siendo un archivo relativamente grande). Por supuesto, existen modelos más pequeños, pero pueden tener capacidades limitadas.
- Suplantación de identidad potenciada por IA: herramientas de clonación de voz y de intercambio de rostros utilizadas en el fraude en tiempo real, la suplantación de ejecutivos y para eludir los procesos de KYC (como se muestra a continuación en la Figura 2).
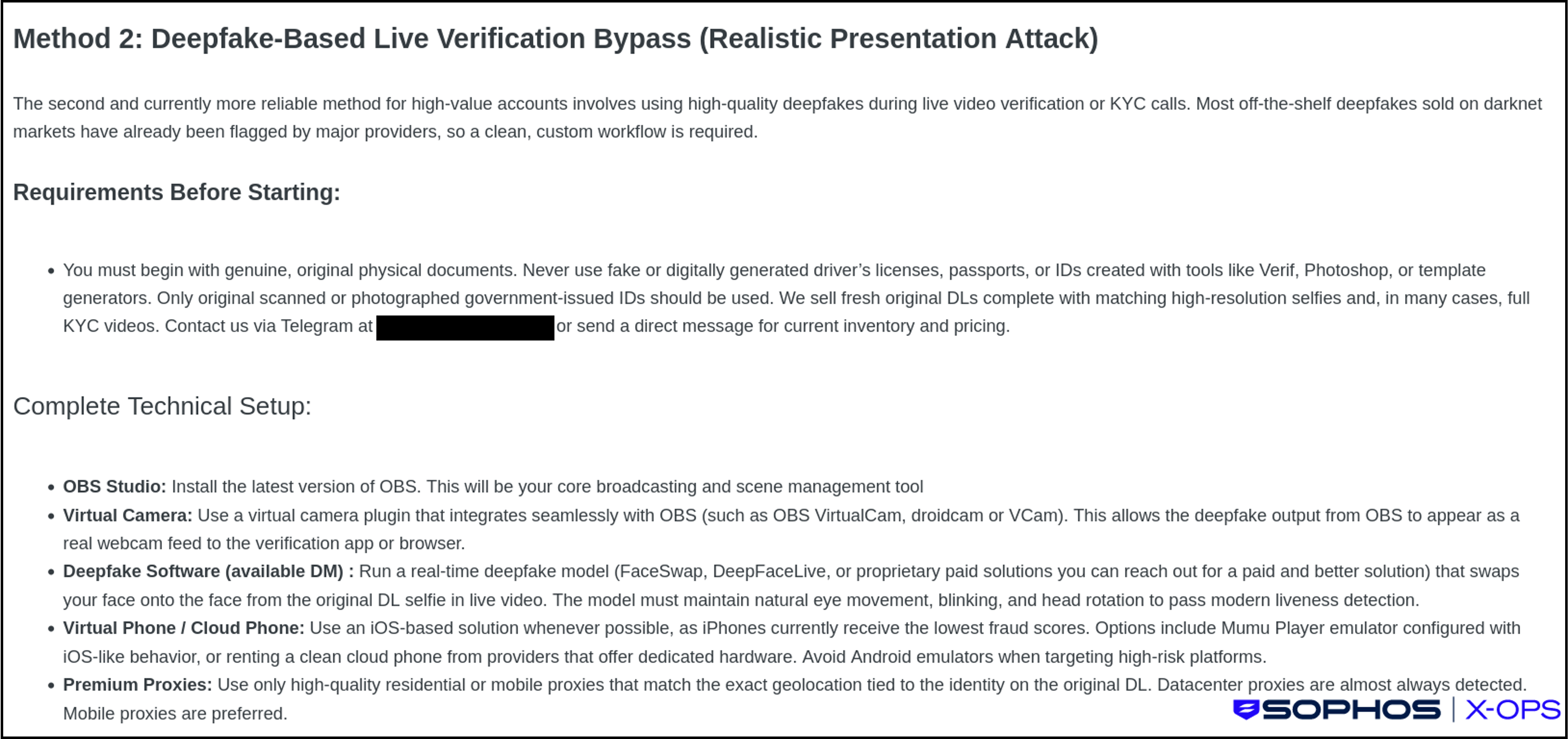
Figura 2: un actor malicioso en un foro criminal describe una configuración para usar deepfakes con el fin de eludir las tecnologías de KYC
Medidas de mitigación
Los defensores detectan con más dificultad estos ataques mediante análisis estático, ya que el comportamiento malicioso es dinámico y se determina en parte en tiempo de ejecución, mediante un modelo que los defensores no pueden ver. Las llamadas a puntos finales de API relacionados con los LLM, las características de los modelos integrados, la secuencia y composición de la ejecución de comandos, y ciertos «indicios» biológicos relacionados con la clonación de voz y el intercambio de rostros pueden ofrecer algunas oportunidades de detección.
Orquestado por IA
Aquí, la IA lleva a cabo las acciones, con una intervención humana mínima, pero con cierto grado de iniciación o supervisión.
- Intrusión orquestada por IA: un agente obtiene o amplía su acceso a través de una red, utilizando (por ejemplo) el Protocolo de Contexto de Modelo. Un operador humano establece un objetivo y el agente ejecuta los pasos. Algunos aspectos de las campañas contra varias organizaciones gubernamentales mexicanas, mencionadas anteriormente, encajan en esta subcategoría. El ejemplo más completo documentado hasta la fecha es GTG-1002, la campaña patrocinada por el Estado chino que Anthropic reveló en noviembre de 2025: aproximadamente treinta objetivos gubernamentales y de infraestructuras críticas, con Claude Code ejecutándose en un equipo con Kali Linux que integraba herramientas de pruebas de penetración de código abierto expuestas como servidores MCP. La IA escaneó los servicios expuestos a Internet, aprovechó una vulnerabilidad SSRF en un servidor web público, recopiló claves SSH y tokens de cuentas de servicios en la nube, y se desplazó lateralmente por el entorno en la nube de la víctima, tomando decisiones tácticas en tiempo real sobre qué explorar a continuación, mientras que el operador humano proporcionaba la dirección estratégica. En el análisis de seguimiento de Anthropic de junio de 2026, lo que distinguió a GTG-1002 no fue el número de técnicas (unas treinta técnicas de MITRE ATT&CK), sino la capa de orquestación que rodeaba al modelo. En la práctica, la orquestación puede abarcar toda la cadena de ataque o solo una parte de ella: un operador podría establecer el acceso inicial manualmente y luego pasarle el relevo a un agente para la fase posterior a la explotación, o bien poner en marcha un agente que dirija la operación de principio a fin. Las implicaciones defensivas son similares en ambos casos.
- Abuso de modelos de lenguaje grande (LLM) orquestado por IA: un actor malicioso contamina o secuestra un flujo de trabajo impulsado por un LLM para distribuir contenido malicioso más adelante a los usuarios
Medidas de mitigación
Estos ataques aún son poco frecuentes en el mundo real, pero suponen un riesgo considerable. Reducen drásticamente el tiempo entre el reconocimiento y la acción, y los modelos de IA no se cansan ni necesitan descansos.
Segunda parte: ataques maliciosos dirigidos a la IA
Los ataques de esta categoría implican que los productos, agentes y ecosistemas de IA se convierten en víctimas (o cómplices involuntarios). Su éxito se debe a la forma en que se construyen y adoptan los sistemas de IA.
Iniciados por el agente
- Compromiso iniciado por el agente: un agente de programación (como Claude Code, Cursor o herramientas del estilo de Copilot) descarga un paquete o dependencia de NPM comprometida mientras realiza su trabajo, o bien un atacante compromete un servidor MCP utilizado por un agente para llevar a cabo actividades maliciosas, como enviar correos con copia oculta (BCC) a una dirección no autorizada. El agente en sí no es malicioso; simplemente se le ha dirigido hacia una cadena de suministro contaminada.
Medidas de mitigación
Lo novedoso aquí no son los ataques a la cadena de suministro; esos son una amenaza bien conocida. La amenaza radica en que el agente acorta el tiempo entre la «publicación del paquete» y la «ejecución del paquete en tu entorno», sin que haya nadie que se detenga a leer el registro de cambios o compruebe los riesgos asociados a los ataques a la cadena de suministro. Las medidas generales de mitigación podrían incluir la limitación de la tasa de acceso, la gestión de la ubicación y la gestión del alcance y los permisos.
Suplantación de identidad de software de IA
- Suplantación de identidad de software de IA: los anuncios maliciosos, los resultados patrocinados, el envenenamiento SEO o las conversaciones compartidas en modelos de lenguaje grande (LLM) manipuladas se aprovechan de los usuarios que buscan herramientas de IA legítimas a un ritmo sin precedentes. El malware que se instala como resultado puede incluir ladrones de información, puertas traseras y mucho más.
Medidas de mitigación
Se trata de un ataque bien conocido, sobre el que llevamos informando desde hace tiempo, pero con señuelos actualizados para aprovechar la demanda de herramientas de IA. Hay dos pilares fundamentales de protección contra este tipo de ataque. Uno es la detección del malware final (y de las cargas útiles intermedias), pero la mejor (y más temprana) forma de defensa es descargar solo aplicaciones e instaladores de sitios web de proveedores legítimos y confirmados.
LLM manipulados
- Manipulación de modelos de lenguaje grande (LLM): un atacante configura un modelo personalizado o inyecta intencionadamente datos maliciosos o adulterados en el proceso de entrenamiento, ajuste fino o recuperación de un modelo para alterar su comportamiento. Aunque todavía no tenemos pruebas de que este ataque se haya producido en la práctica, los investigadores lo han demostrado teóricamente, y los atacantes ya han utilizado modelos de aprendizaje automático como arma, aunque fuera para distribuir puertas traseras «tradicionales» a través de archivos «pickle».
Medidas de mitigación
Desconfía de los enlaces que te den los modelos de IA: comprueba que apunten a dominios legítimos y desconfía de cualquier instrucción que te pida copiar y pegar contenido en un terminal o ventana de comandos (sobre todo si el contenido está ofuscado).
Ataques al modelo
Mientras que los ataques descritos anteriormente se dirigen al ecosistema de la IA (instaladores, mensajes de solicitud, etc.), este tipo de ataque se centra en los propios modelos de IA: pesos, datos de entrenamiento y límites de decisión.
- Extracción de modelos: los actores maliciosos interrogan repetidamente un modelo desplegado hasta que pueden reconstruir una copia aproximada mediante destilación, robando así el activo y socavando cualquier ventaja competitiva basada en el coste del entrenamiento
- Inversión de datos de entrenamiento: las consultas diseñadas extraen datos de entrenamiento de un modelo desplegado, sobre todo cuando los corpus de entrenamiento incluyen material sensible, como datos personales, código propietario o texto protegido por derechos de autor
- Ejemplos adversarios:entradas diseñadas para engañar a un modelo y que realice una clasificación errónea, aunque parezcan inofensivas (u obvias) para un humano. Históricamente —y desde hace ya varios años—, estos han incluido pequeños cambios adversarios en la señalización vial, pero los ataques pueden generalizarse a modelos de texto, audio y multimodales
- Inferencia de pertenencia: Determinar si un registro específico formaba parte de un conjunto de entrenamiento, aprovechando la tendencia del modelo a tener más confianza en los datos que ya ha visto antes. Se trata de un ataque a la privacidad y un motivo de preocupación para cualquier organización que entrene con datos de clientes.
Medidas de mitigación
Estas son las técnicas que MITRE ATLAS aborda con mayor profundidad, y las que menos probabilidades tienen de aparecer en la telemetría estándar; a menudo parecen actividad normal a menos que y hasta que se midan los patrones de consulta agregados a lo largo del tiempo.
Cómo usar esta taxonomía
Como hemos señalado antes, también hay muchas otras iniciativas en este campo, siendo MITRE ATLAS quizás el vocabulario compartido más destacado para la inteligencia sobre amenazas de IA. A partir de la versión 5.10 (noviembre de 2025), cataloga 16 tácticas y 84 técnicas basadas en la cadena de ataque de ATT&CK, con actualizaciones continuas hasta 2026 que añaden cobertura sobre la IA autónoma.
Sin embargo, ATLAS se centra en los ataques maliciosos dirigidos a la IA. Eso abarca nuestra segunda parte, y nuestras subcategorías se corresponden con técnicas de ATLAS como Compromiso de la cadena de suministro de la IA, Inyección de prompts en LLM, y Manipulación de modelos de IA. Pero los ataques que utilizan la IA —tratados en nuestra primera parte— se sitúan en los márgenes del marco de ATLAS, en lugar de en su centro.
Esta laguna no es exclusiva de ATLAS. Anthropic llegó a una conclusión similar a nivel más amplio de ATT&CK en su informe «LLM ATT&CK Navigator» de junio de 2026: los comportamientos autónomos y con capacidad de agente que distinguen a los actores más capaces —la orquestación de la cadena de ataque, las decisiones de pivote en tiempo real, la ejecución dirigida por IA— aún no tienen identificadores de técnica en el marco. El problema de vocabulario no es solo nuestro, y es probable que los marcos relevantes evolucionen.
La distinción entre las dos categorías de nuestra taxonomía es importante, porque requieren posturas defensivas diferentes. El uso malicioso de la IA es un problema de productividad y volumen; las soluciones de detección existentes pueden detectar muchas cosas, pero el problema es la escala y la velocidad a la que las campañas se repiten y se adaptan. Por otro lado, los ataques maliciosos dirigidos a la IA son más bien una cuestión de confianza y de la cadena de suministro, y suele ser más adecuado abordarlos con políticas, marcos de «seguridad desde el diseño» e iniciativas similares.
Además, tratarlas por separado ofrece una visión más clara y precisa de la amenaza. «Los incidentes relacionados con la IA han aumentado un 300 %» no significa nada si esa estadística mezcla un correo de phishing creado por GPT con un agente de programación que, sin darse cuenta, introdujo una dependencia con puerta trasera en el entorno de producción.
En definitiva, te sugerimos que veas nuestra taxonomía como un complemento a otras, en lugar de un sustituto. Los defensores pueden usar la nuestra en la fase inicial, cuando necesitan una etiqueta rápida e inequívoca para un incidente en curso, y luego complementarla con un análisis más detallado en ATLAS para descomponer la cadena de ataque, trazar la mitigación y compartirla externamente con partners y clientes. O, dependiendo de las características específicas del incidente, con información de la taxonomía de agentes de IA de Microsoft, el Repositorio de Riesgos del MIT o la taxonomía del NIST sobre aprendizaje automático adversario.
Como hemos señalado antes, esta taxonomía no debe considerarse completa. Todo intento tiene lagunas, y el campo de la IA evoluciona a un ritmo especialmente rápido. Surgirán nuevos patrones y clases de ataques (por ejemplo: reconocimiento autónomo, ataques de agente contra agente, extracción de modelos a gran escala) y puede que haya que fusionar o redefinir el contenido existente.
Pero lo importante es comprometerse con la disciplina de una taxonomía: cuando se produzca un incidente, etiquétalo de forma específica, distingue quién está usando qué contra quién y deja que los datos hablen por sí mismos.